2024

Multi-ToM: Evaluating Multilingual Theory of Mind Capabilities in Large Language Models
Jayanta Sadhu, Ayan Antik Khan (BUET), Noshin Nawal, Sanju Basak, Abhik Bhattacharya (BUET)
Details: This research project is to examine the cognitive capabilities of Large Language Models(LLM) in the domain Theory of Mind(ToM) test across languages. The objective of this project is to ascertain the capabilities of LLMs in the setup of multilingual ToM questionnaire. We also want to study if the inclusion of cultural elements specific to languages changes the performance of the LLMs in terms of cognitive abilities. Had the opportunity to supervise two junior students in this project.
An Empirical Study of Gendered Stereotypes in Emotional Attributes for Bangla in Multilingual Large Language Models
Jayanta Sadhu, Maneesha Rani Saha (BUET), Dr. Rifat Shahriyar (Professor, BUET)
Details: In this study, we conducted a research that investigated gendered stereotypes in emotional attributes within multilingual large language models (LLMs) for Bangla. The study analyzed historical patterns, revealing how women were often associated with emotions like empathy and guilt, while men were linked to emotions such as anger and authority in Bangla-speaking regions. We evaluated both closed and open-source LLMs to identify gender biases in emotion attribution. The project included qualitative and quantitative analysis of LLM responses to Bangla gender attribution tasks and highlighted the influence of gendered role selection on these outcomes. We also developed and publicly shared datasets and code to support further research in Bangla NLP. Please refer to the paper link for more details.
Social Bias in Large Language Models For Bangla: An Empirical Study on Gender and Religious Bias
Jayanta Sadhu, Maneesha Rani Saha (BUET), Dr. Rifat Shahriyar (Professor, BUET)
Details: This research project, supervised by Dr. Rifat Shahriyar, focused on examining social biases in large language models (LLMs) for the Bangla language. The study involved investigating two distinct types of social biases in Bangla LLMs. We developed a curated dataset to benchmark bias measurement and implemented two probing techniques for bias detection. This work represents the first comprehensive bias assessment study for Bangla LLMs, with all code and resources made publicly available to support further research in bias detection for Bangla NLP. Please refer to the paper link for more details.
An Empirical Study on the Characteristics of Bias upon Context Length Variation for Bangla
Jayanta Sadhu*, Ayan Antik Khan (BUET)*, Abhik Bhattacharya (BUET), Dr. Rifat Shahriyar (Professor, BUET) (* equal contribution)
Details: This research project, which formed the basis of my undergraduate thesis under the supervision of Dr. Rifat Shahriar, explored the nuances of gender bias detection in Bangla language models. We constructed a curated dataset for detecting gender bias in both static and contextual setups and compared different bias detection methods specifically tailored to Bangla. The study established benchmark statistics using baseline methods and analyzed bias in various language models supporting Bangla, including BanglaBERT, MuRIL, and XML-RoBERTa. A key focus was understanding how the context length of templates and sentences affects bias detection outcomes. This work serves as a foundational study for bias detection in Bangla language models. Please refer to the paper link for more details.
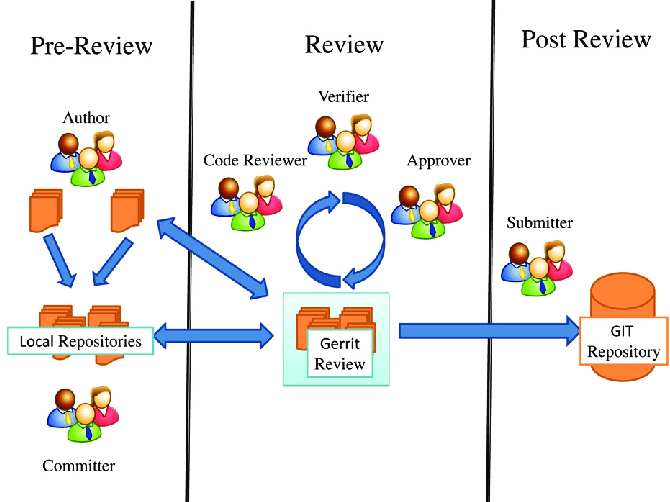
Code Review Generation Automation using LLM and Preference Optimization
Jayanta Sadhu, Sadat Shahriyar, Dr. Anindya Iqbal (Professor, BUET)
Details: This is an ongoing project of mine under the supervision of Dr. Anindya Iqbal. Our aim here is to produce more human like reviews and automating review generation procedure through large language models. We are working on the latest RL based preference optimization to finetune SOTA open source LLMs and figure out more suitable evaluation metric to find out human likeliness of code review. The knowledge domains we need in this study are: Code review, LLM inference, LLM finetuning and Objective evaluation.
2023
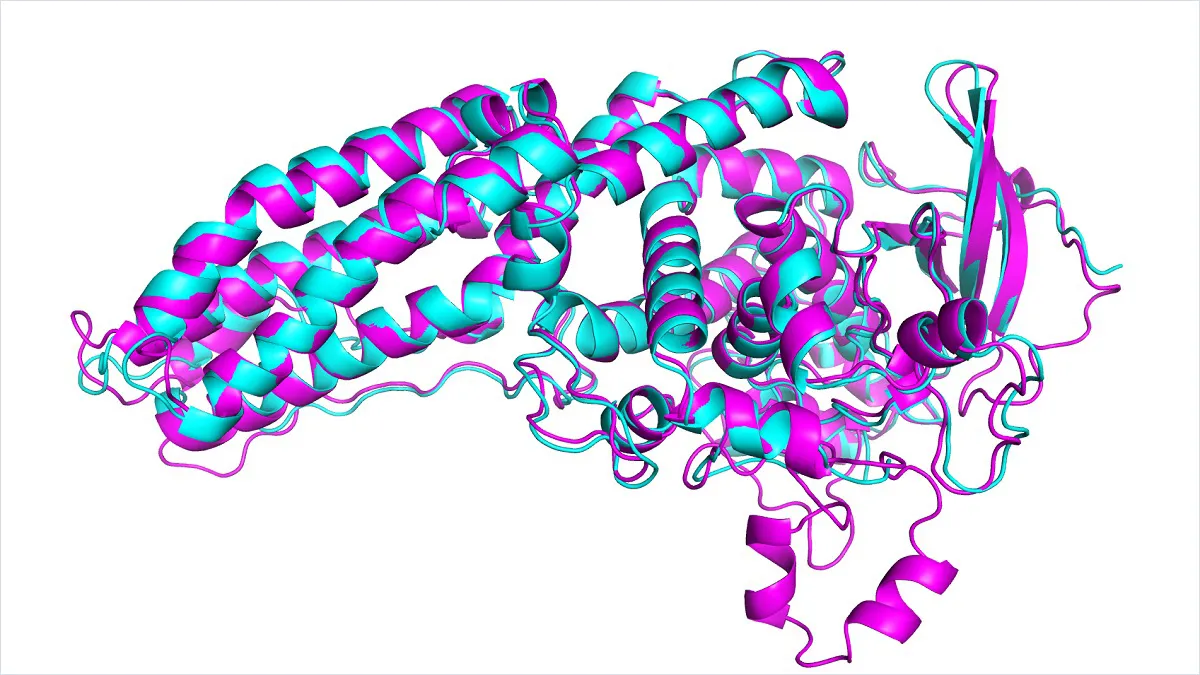
Reinforcement Learning based Fine-tuning for Protein Folding Prediction Models
Abstract: This research project, conducted between November 2023 and January 2024, focused on improving inference time for protein folding predictions using advanced protein folding models. We utilized reinforcement learning-based fine-tuning of large language models to achieve both low-resource training and targeted performance improvements. The project required expertise in protein sequencing and folding models such as AlphaFold and ESM, as well as skills in designing loss functions. The technical stack included PyTorch, biotite-python, omegaconf, hydra-core, and transformers.
Abstractive Summarization of Bangla Using Language Generative Model with Constrastive Learning
Jayanta Sadhu, Tanjim Ahmed Khan (BUET), Dr. Saifur Rahman (Professor, BUET)
Details: This is a research project that I did as a part of my coursework in Machine Learning Sessional course, supervised by Dr. Saifur Rahman. The project's goal was to generate abstractive summaries of Bangla text using a Bangla language generative model. To improve the model's performance and surpass the current state-of-the-art (SOTA) models in Bangla, we implemented contrastive learning techniques. Our work was guided by concepts from the BRIO paper, which served as a key reference throughout the project.